frontend-notes
浏览器从输入网址到页面展现的整个过程
服务器监听
浏览器输入的是一个网络地址,如果该网址有效,那么该网址对应的其实是一个连接到网络的服务器,浏览器访问网址的过程其实就是找到这个服务器ip地址,然后从该服务请ip地址请求资源的过程 这个服务器在浏览器访问前就已经做好了准备等待网络中任何一台电脑去访问它,具体步骤为
- 随着服务器上电、操作系统的准备就绪,服务器会启动 http服务进程(这个 http 服务的守护进程(daemon),可能是 Apache、Nginx、IIS、Lighttpd中的一个)
- http 服务进程开始定位到服务器上的 www 文件夹(网站根目录),一般是位于 /var/www
- 然后启动了一些附属的模块,例如 php,或者,使用 fastcgi 方式连接到 php 的 fpm 管理进程
- 然后,向操作系统申请了一个 tcp 连接,然后绑定在了 80 端口,调用了 accept 函数,开始了默默的监听,监听着可能来自位于地球任何一个地方的请求,随时准备做出响应。
这个时候,典型的情况下,机房里面应该还有一个数据库服务器,或许,还有一台缓存服务器,如果对于流量巨大的网站,那么动态脚本的解释器可能还有单独的物理机器来跑,如果是中小的站点,那么,上述的各色服务,甚至都可能在一台物理机上,这些服务监听之间的关系,可以通过自己搭建一次 Apache PHP MySQL 环境来了解一下,不管怎么说,他们做好了准备,静候差遣。
1. 客户端输入网址
用户输入网址时浏览器可能会做一些预处理,甚至已经在智能匹配所有可能的URL了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应的URL,来预估所输入字符对应的网站,然后给出智能提示,比如输入了「ba」,根据之前的历史发现 90% 的概率会访问「www.baidu.com 」,因此就会在输入回车前就马上开始建立 TCP 链接了。对于 Chrome这种变态的浏览器,他甚至会直接从缓存中把网页渲染出来,就是说,你还没有按下「回车」键,页面就已经出来了,再比如Chrome会在浏览器启动时预先查询10个你有可能访问的域名等等,这里面还有很多其它策略,不详细讲了。
URL完整格式为:
协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志,例如:https://www.zhihu.com/question/55998388/answer/166987812的协议是https,网络地址为www.zhihu.com(依次为 子/三级域名.二级域名.顶/一级域名),资源路径为/question/55998388/answer/166987812
按下回车后,如果是一个网址是一个域名时则需要进行域名解析。因为网络通讯大部分是基于TCP/IP的,而TCP/IP是基于IP地址的,所以计算机在网络上进行通讯时只能识别如“202.96.134.133”之类的IP地址,而不能认识域名。而将域名解析为一个ip地址的过程就叫域名解析。
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工作。DNS就是这样的一位“翻译官” DNS是应用层协议,事实上他是为其他应用层协议工作的,包括不限于HTTP和SMTP以及FTP,用于将用户提供的主机名解析为ip地址。
2. 域名解析
浏览器对 URL 进行检查时首先判断协议,如果是 http/https 就按照 Web 来处理,另外还会对 URL 进行安全检查,然后直接调用浏览器内核中的对应方法,接下来是对网络地址进行处理,如果地址不是一个IP地址而是域名则通过DNS(域名系统)将该地址解析成IP地址。IP地址对应着网络上一台计算机,DNS服务器本身也有IP,你的网络设置包含DNS服务器的IP。 例如:www.zhihu.com域名请求对应获得的IP是 116.211.167.187。DNS 在解析域名的时候有两种方式:递归查询和迭代查询
- 递归查询:浏览器到本地DNS服务器的过程就是递归查询,浏览器发起查询后啥事都不用干,一直等待,知道本地DNS服务器返回结果(“查询的递交者” 一直在更替)
- 迭代查询:本地DNS服务器到根域名服务器查询的方式,由本地DNS服务器不停地向不同的服务器查询,最终才能得到想要的结果(“查询的递交者” 一直没变化)
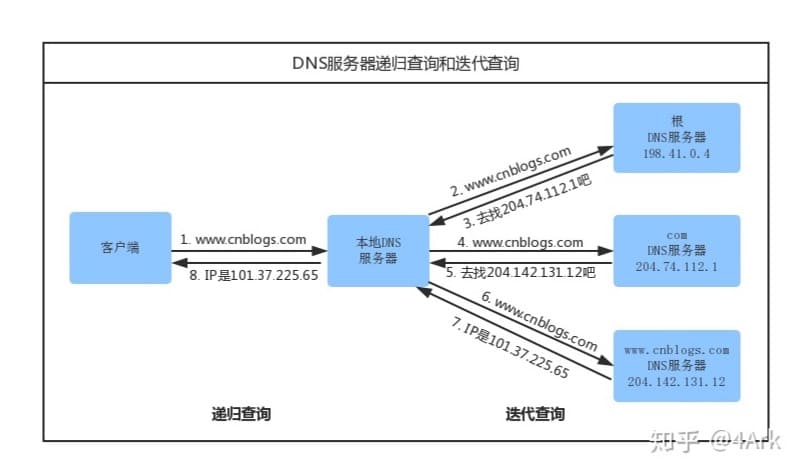
如上图就是浏览器使用的是递归查询的整个过程(查询过程中,本地服务器使用的是迭代查询),我们可以看到上面有各种类型的服务器,这就涉及到 DNS名称服务器的种类,dns名称服务器自高到低分为4个级别:根名称服务器、顶级名称服务器、权威名称服务器和本地域名服务器
- 根名称服务器 根名称服务器是由互联网管理机构配置建立的,是最高层次的名称服务器,负责对互联网所有“顶级名称服务器”进行管理,有全部顶级名称服务器的IP地址和域名映射。 全球共有13套(而不是13个,很多人平常说是13个,其实是错误的,据说已经有上千台了,好多台用于负载均衡,备份等),但每套都只有一个主根名称服务器。其中10台在美国,2台在欧洲,一台在日本。名称分别从a-m,分别为a.rootserver.net-m.rootserver.net,其余均为辅根,在全球各地,中国好像是有4个辅根,或者叫做镜像也可以。 根名称服务器并不直接用于名称解析,因为其没有保存全部互联网域名记录,只是负责顶级名称服务器相关内容。
- 顶级名称服务器 “顶级名称服务器”是各顶级域名自己的名称服务器,负责他们各自管理的二级域名解析。
- 权威名称服务器 “权威名称服务器”是针对dns区域提供名称解析服务而专门配置、建立的名称服务器,可为用户提供最权威的dns域名解析。每个域名在互联网上都可以找到一台权威服务器,个人理解一台权威服务器可以为很多域名提供域名解析。
- 本地名称服务器
一般是指ISP(互联网服务提供商,Internet Service Provider的简称,如电信运营商电信、联通、移动)提供的名称服务器(也就是本地DNS服务器,不同运营商提供的IP地址可能不一样,这涉及到负载均衡,通过DNS解析域名时会将你的访问分配到不同的入口,先找附近的本地 DNS 服务器去请求解析域名,尽可能保证你所访问的入口是所有入口中较快的一个),一般是客户端电脑TCP/IP参数中设置的首选DNS服务器,例如我们使用的
114.114.114.114,Google的8.8.8.8,都是本地名称服务器。
搞清楚服务器名称种类后,接下来我们就可以一步步分析域名解析的具体细节
a. 浏览器查询本地缓存
- 查询浏览器缓存
- DNS 在各个层级都有缓存的,相应的,缓存当然有过期时间,Time to live
- 检查系统缓存
- 检查本地硬盘的hosts文件
- 这个文件保存了一些以前访问过的网站的域名和IP对应的数据。它就像是一个本地的数据库。如果找到就可以直接获取目标主机的IP地址了(注意这个地方存在安全隐患,如果有病毒把一些常用的域名,修改 hosts 文件,指向一些恶意的IP,那么浏览器也会不加判断的去连接,是的,这正是很多病毒的惯用手法)
- 再向上层找查询路由器缓存
- 路由器有自己的DNS缓存,可能就包括了查询的内容
b. 浏览器向本地名称服务器发起递归查询
- 如果以上步骤都没找到,浏览器将发起一个DNS的系统调用,向
本地名称服务器(一般是运营商提供的,本地配置的首选DNS服务器)发送查询消息查询(通过的是UDP协议向DNS的53端口发起请求),该查询是一个递归查询,意思就是浏览器会一直等待本地名称服务器返回结果
c. 本地名称服务器发起迭代查询
- 查询
本地名称服务器缓存本地名称服务器会先查找自身的缓存,如果存在则返回
本地名称服务器代我们的浏览器发起迭代查询本地名称服务器向根名称服务器IP地址发起请求,它只是负责顶级名称服务器(如.com/.cn/.net等)的相关内容。所以它会把所查询得到的被请求的DNS域名中顶级域名所对应的顶级名称服务器IP地址返回给本地名称服务器本地名称服务器向顶级名称服务器IP地址发起请求,顶级名称服务器在收到DNS查询请求后,也是先查询自己的缓存,如果有则直接把对应的记录项返回给本地名称服务器,然后再由本地名称服务器返回给DNS客户端,如果没有则向本地名称服务器返回所请求的DNS域名中的二级域名所对应的二级名称服务器(如baidu.com/qq.com/net.cn等)地址,然后本地名称服务器继续按照前面介绍的方法一次次地向三级(如www.baidu.com/www.qq.com/bbs.taobao.com等)、四级名称服务器查询,直到最终的对应域名所在区域的权威名称服务器权威名称服务器返回最终记录给本地名称服务器。同时本地名称服务器会缓存本次查询得到的记录项(每层都应该会缓存)。再层层下传,最后到了我们的DNS客户端机子,一次 DNS 解析请求就此完成。如果最终权威名称服务器都说找不到对应的域名记录,则会向本地名称服务器返回一条查询失败的DNS应答报文,这条报文最终也会由本地名称服务器返回给DNS客户端。当然,如果这个权威名称服务器上配置了指向其它名称服务器的转发器,则权威名称服务器还会在转发器指向的名称服务器上进一步查询。另外,如果DNS客户端上配置了多个DNS服务器,则还会继续向其它DNS服务器查询的。
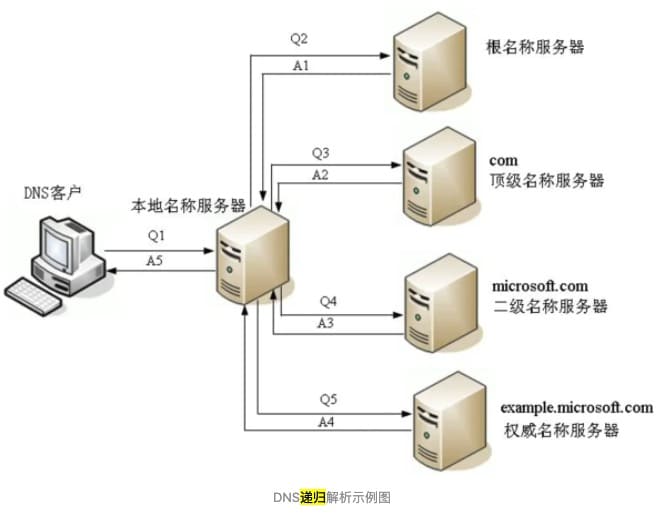
我们看到DNS的域名解析是递归的,递归的DNS首先会查看自己的DNS缓存,如果缓存能够命中,那么就从缓存中把IP地址返回给浏览器,如果找不到对应的域名的IP地址,那么就依此层层向上转发请求,从根域名服务器到顶级域名服务器再到极限域名服务器依次搜索对应目标域名的IP,最高达到根节点,找到或者全部找不到为止。然后把找到的这个域名对应的 nameserver 的地址拿到,再向这个 namserver 去请求域名对应的IP,最后把这个IP地址返回给浏览器,在这个递归查询的过程中,对于浏览器来说是透明的,如果DNS客户端的本地名称服务器不能解析的话,则后面的查询都会以本地名称服务器为中心,全交由本地名称服务器代替DNS客户端进行查询,DNS客户端只是发出原始的域名查询请求报文,然后就一直处于坐等状态,直到本地名称服务器最终从权威名称服务器得到了正确的IP地址查询结果并返回给它。
如上就是浏览器使用递归查询的整个过程,如果浏览器使用迭代查询,结果会怎样呢?
DNS查询默认使用的是递归查询,但是如果有以下情况发生的话,则会使用迭代的查询方式进行。
- 情况一:DNS客户端的请求报文中没有申请使用递归查询,即在DNS请求报头部的RD字段没有置1。
- 情况二:DNS客户端的请求报文中申请使用的是递归查询(也就是RD字段置1了),但在所配置的本地名称服务器上是禁用递归查询了(即在应答DNS报文头部的RA字段置0)。
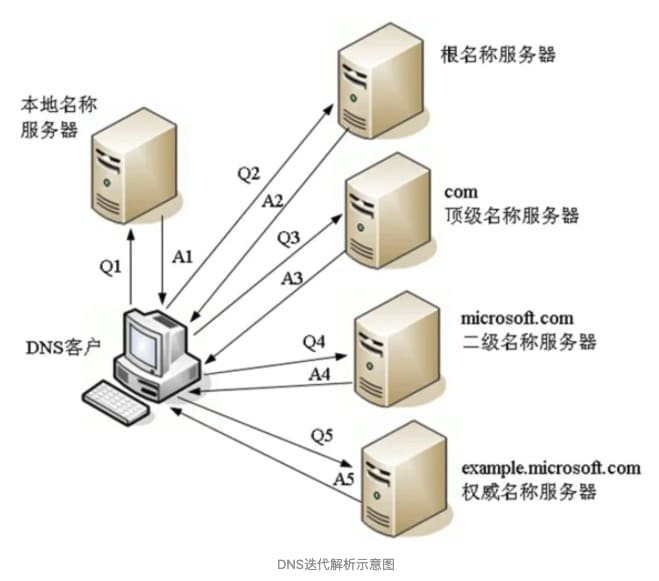
浏览器迭代查询
如果浏览器一开始使用的就是迭代查询,那么过程如下图所示
3. 应用层客户端发送HTTP请求
互联网内各网络设备间的通信都遵循TCP/IP协议,利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信。分层由高到低分别为:应用层、传输层、网络层、数据链路层。发送端从应用层往下走,接收端从数据链路层网上走。如下:
客户端 服务器
应用层 http客户端 http客户端
↕ ↕
传输层 TCP TCP
↕ ↕
网络层 IP IP
↕ ↕
数据链路层 网络 网络
↖_________________↗️
从上面的步骤中得到 IP 地址后,浏览器会开始构造一个 HTTP 请求,应用层客户端向服务器端发送的HTTP请求包括:请求报头和请求主体两个部分,其中请求报头(request header)包含了至关重要的信息,包括请求的方法(GET / POST和不常用的PUT / DELETE以及更不常用的HEAD / OPTION / TRACE,一般的浏览器只能发起 GET 或者 POST 请求)、目标url、遵循的协议(HTTP / HTTPS / FTP…),返回的信息是否需要缓存,以及客户端是否发送Cookie等信息。需要注意的是,因为 HTTP 请求是纯文本格式的,所以在 TCP 的数据段中可以直接分析 HTTP 文本的。
4. 传输层TCP传输报文
当应用层的 HTTP 请求准备好后,浏览器会在传输层发起一条到达服务器的 TCP 连接,位于传输层的TCP协议为传输报文提供可靠的字节流服务。它为了方便传输,将大块的数据分割成以报文段为单位的数据包进行管理,并为它们编号,方便服务器接收时能准确地还原报文信息。TCP协议通过“三次握手”等方法保证传输的安全可靠。
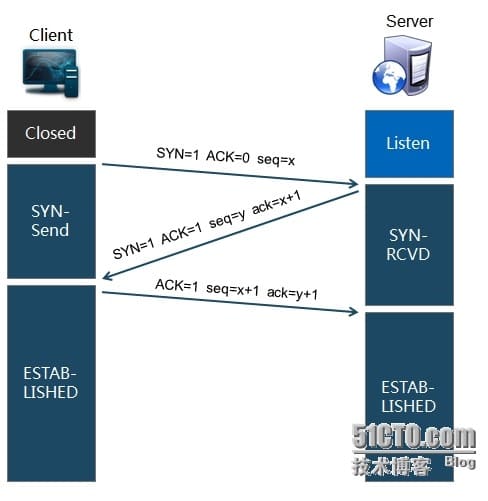
三次握手
“三次握手”的过程是,发送端先发送一个带有SYN(synchronize)标志的数据包给接收端,在一定的延迟时间内等待接收的回复。接收端收到数据包后,传回一个带有SYN/ACK标志的数据包以示传达确认信息。接收方收到后再发送一个带有ACK标志的数据包给接收端以示握手成功。在这个过程中,如果发送端在规定延迟时间内没有收到回复则默认接收方没有收到请求,而再次发送,直到收到回复为止。
- Client 发送
SYN=1 [ACK=0] seq=x给 Service,Client进入syn_sent状态,表示客户端等待服务器的回复- ACK=0 表示确认号无效
- SYN = 1 表示这是一个连接请求或连接接受报文,同时表示这个数据报不能携带数据
- seq = x 表示Client自己的初始序号(是一个随机产生的序号值)
- Service 发送
SYN=1 ACK=1 seq=y ack=x+1给 Client,服务器进入syn_rcvd,表示服务器已经收到Client的连接请求,等待client的确认- TCP报文首部中的 SYN 和 ACK都置1
- seq = y 表示Server 自己的初始序号(是一个随机产生的序号值)
- ack = x + 1表示期望收到对方下一个报文段的第一个数据字节序号是x+1,同时表明x为止的所有数据都已正确收到
- Client 发送
ACK=1 [seq=x+1] ack=y+1给 Service,一旦收到Client的确认之后,这个TCP连接就进入Established状态,就可以发起http请求了。- ACK 置1 表示确认号ack= y + 1 有效(代表期望收到服务器的第1个包)
- Client自己的序号seq= x + 1(表示这就是我的第1个包,相对于第0个包来说的)
记忆方法:
- SYN 是客户端 用于跟服务端同步的标识位
- ACK 是接收方(Client/Service)用于告诉发送方(Service/Client)我正确接收了,是对上一个包的确认操作
- seq 是发送方的序号,第一次发送的时候是个随机数
- ack 是接收方接收到的序号+1,是对上一个包的序号进行确认的号,ack=seq+1。
SYN这个标志位只有在TCP建立连接时才会被置1 ,握手完成后SYN标志位被置0。???
这里需要谈一下 TCP 的 Head-of-line blocking 问题:假设客户端的发送了 3 个 TCP 片段(segments),编号分别是 1、2、3,如果编号为 1 的包传输时丢了,即便编号 2 和 3 已经到达也只能等待,因为 TCP 协议需要保证顺序,这个问题在 HTTP pipelining 下更严重,因为 HTTP pipelining 可以让多个 HTTP 请求通过一个 TCP 发送,比如发送两张图片,可能第二张图片的数据已经全收到了,但还得等第一张图片的数据传到。为了解决 TCP 协议的性能问题,Chrome 团队提出了 QUIC 协议,它是基于 UDP 实现的可靠传输,比起 TCP,它能减少很多来回(round trip)时间,还有前向纠错码(Forward Error Correction)等功能。目前 Google Plus、 Gmail、Google Search、blogspot、Youtube 等几乎大部分 Google 产品都在使用 QUIC,可以通过chrome://net-internals/#spdy 页面来发现。另外,浏览器对同一个域名有连接数限制,大部分是 6,但并非将这个连接数改大后就会提升性能,Chrome 团队有做过实验,发现从 6 改成 10 后性能反而下降了,造成这个现象的因素有很多,如建立连接的开销、拥塞控制等问题,而像 SPDY、HTTP 2.0 协议尽管只使用一个 TCP 连接来传输数据,但性能反而更好,而且还能实现请求优先级。
5. 网络层IP协议查询MAC地址
IP协议的作用是把TCP分割好的各种数据包封装到IP包里面传送给接收方。而要保证确实能传到接收方还需要接收方的MAC地址,也就是物理地址才可以。IP地址和MAC地址是一一对应的关系,一个网络设备的IP地址可以更换,但是MAC地址一般是固定不变的。ARP协议可以将IP地址解析成对应的MAC地址。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的MAC地址来搜索下一个中转目标。
6. 数据到达数据链路层
在找到对方的MAC地址后,已被封装好的IP包再被封装到数据链路层的数据帧结构中,将数据发送到数据链路层传输,再通过物理层的比特流送出去。这时,客户端发送请求的阶段结束。
这些分层的意义在于分工合作,数据链路层通过 CSMA/CD 协议保证了相邻两台主机之间的数据报文传递,而网络层的 IP 数据包通过不同子网之间的路由器的路由算法和路由转发,保证了互联网上两台遥远主机之间的点对点的通讯,不过这种传输是不可靠,于是可靠性就由传输层的 TCP 协议来保证,TCP 通过慢开始,乘法减小等手段来进行流量控制和拥塞避免,同时提供了两台遥远主机上进程到进程的通信,最终保证了 HTTP 的请求头能够被远方的服务器上正在监听的 HTTP 服务器进程收到,终于,数据包在跳与跳之间被拆了又封装,在子网与子网之间被转发了又转发,最后进入了服务器的操作系统的缓冲区,服务器的操作系统由此给正在被阻塞住的 accept 函数一个返回,将他唤醒。
7. 服务器接收数据
接收端的服务器在链路层接收到数据包,再层层向上直到应用层。这过程中包括在传输层通过TCP协议将分段的数据包重新组成原来的HTTP请求报文。
8. 服务器响应请求并返回相应文件
服务接收到客户端发送的HTTP请求后,服务器上的的 http 监听进程会得到这个请求,然后一般情况下会启动一个新的子进程去处理这个请求,同时父进程继续监听。http 服务器首先会查看重写规则,然后如果请求的文件是真实存在,例如一些图片,或 html、css、js 等静态文件,则会直接把这个文件返回,如果是一个动态的请求,那么会根据 url 重写模块的规则,把这个请求重写到一个 rest 风格的 url 上,然后根据动态语言的脚本,来决定调用什么类型的动态文件脚本解释器来处理这个请求。最终服务器会封装一个标准的 http 响应包,再通过 tcp ip 协议,送回到客户机浏览器。
9. 浏览器开始处理数据信息并渲染页面
历经千辛万苦,我们请求的响应终于成功到达了客户端的浏览器,响应到达浏览器之后,浏览器首先会根据返回的响应报文里的一个重要信息——状态码,来做个判断。如果是 200 开头的就好办,表示请求成功,直接进入渲染流程,如果是 300 开头的就要去相应头里面找 location 域,根据这个 location 的指引,进行跳转,这里跳转需要开启一个跳转计数器,是为了避免两个或者多个页面之间形成的循环的跳转,当跳转次数过多之后,浏览器会报错,同时停止。比如:301表示永久重定向,即请求的资源已经永久转移到新的位置。在返回301状态码的同时,响应报文也会附带重定向的url,客户端接收到后将http请求的url做相应的改变再重新发送。如果是 400 开头或者 500 开头的状态码,浏览器也会给出一个错误页面。比如:404 not found 就表示客户端请求的资源找不到。 当浏览得到一个正确的 200 响应之后,根据响应头里面指定的 encoding 去解析字符,然后去构建dom树,具体细节看DOM树构建中的总结。
构建出来的 dom 本质上还是一棵抽象的逻辑树,构建 dom 树的过程中,如果遇到了由 script 标签包起来的 js 动态脚本代码,那么会把代码送到 js 引擎里面去跑,如果遇到了 style 标签包围起来的 css 代码,也会保存下来,用于稍后的渲染。如果遇到了 img 或 css 和 js等引用外部文件的标签,那么浏览器会根据指定的 url 再次发起一个新的 http 请求,去把这个文件拉取回来,值得一提的是,对于同一个域名下的下载过程来说,浏览器一般允许的并发请求是有限的,通常控制在两个左右,所以如果有很多的图片的话,一般出于优化的目的,都会把这些图片使用一台静态文件的服务器来保存起来,负责响应,从而减少主服务器的压力。 dom 树构造好了之后,就是根据 dom 树和 css 样式表来构造 render 树了,这个才是真正的用于渲染到页面上的一个一个的矩形框的树,网页渲染是浏览器最复杂、最核心的功能,对于 render 树上每一个框,需要确定他的 x y 坐标,尺寸,边框,字体,形态,等等诸多方面的东西,render 树一旦构建完成,整个页面也就准备好了,可以上菜了。需要说明的是,下载页面,构建 dom 树,构建 render 树这三个步骤,实际上并不是严格的先后顺序的,为了加快速度,提高效率,让用户不要等那么久,现在一般都并行的往前推进的,现代的浏览器都是一边下载,下载到了一点数据就开始构建 dom 树,也一边开始构建 render 树,构建了一点就显示一点出来,这样用户看起来就不用等待那么久了
10. 将渲染好的页面图像显示出来,并开始响应用户的操作。
这一步主要涉及显卡,内存及显示器原理等知识,不做详细解说
总结
一次完整的HTTP事务是怎样一个过程?
- 域名解析
- 发起TCP的3次握手
- 建立TCP连接后发起http请求
- 服务器响应http请求,浏览器得到html代码
- 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)
- 浏览器对页面进行渲染呈现给用户
相关知识点
一次完整的HTTP请求所经历的7个步骤
- 建立TCP连接 在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建 Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则, 只有低层协议建立之后才能,才能进行高层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。
- Web浏览器向Web服务器发送请求行 一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令。例如:GET /sample/hello.jsp HTTP/1.1。
- Web浏览器发送请求头 浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
- Web服务器应答 客户机向服务器发出请求后,服务器会客户机回送应答, HTTP/1.1 200 OK ,应答的第一部分是协议的版本号和应答状态码。
- Web服务器发送应答头 正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
- Web服务器向浏览器发送数据 Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据。
- Web服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码:
Connection:keep-alive。
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
建立TCP连接->发送请求行->发送请求头->(到达服务器)发送状态行->发送响应头->发送响应数据->断TCP连接
为什么需要DNS解析域名为IP地址?
网络通讯大部分是基于TCP/IP的,而TCP/IP是基于IP地址的,所以计算机在网络上进行通讯时只能识别如“202.96.134.133”之类的IP地址,而不能认识域名。我们无法记住10个以上IP地址的网站,所以我们访问网站时,更多的是在浏览器地址栏中输入域名,就能看到所需要的页面,这是因为有一个叫“DNS服务器”的计算机自动把我们的域名“翻译”成了相应的IP地址,然后调出IP地址所对应的网页。
具体什么是DNS?
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工作。DNS就是这样的一位“翻译官” DNS是应用层协议,事实上他是为其他应用层协议工作的,包括不限于HTTP和SMTP以及FTP,用于将用户提供的主机名解析为ip地址。
URI、URL、URN是什么
- URI(统一资源标识符, Uniform Resource Identifier )
- 就是在某一规则下能把一个资源独一无二地标识出来。
- URL(统一资源定位符, Uniform Resource Locator)
- 一個在互聯網上查找指定資源(例如網頁,圖片或視頻)位置的文本字符串。俗称网址,就是浏览器地址栏里面的。
- URN(统一资源名称,Uniform Resource Name)
- 用命名空間允許的名稱指向資訊來源,例如國際標準書碼 (International Standard Book Number,一般以ISBN 縮寫)
URL 和 URN 本质上也是一个URI
URL完整格式为:
协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志,例如:https://www.zhihu.com/question/55998388/answer/166987812的协议是https,网络地址为www.zhihu.com(依次为 子/三级域名.二级域名.顶/一级域名),资源路径为/question/55998388/answer/166987812
HTTP格式
- 请求报文
- 请求行
- 组成
- 请求方法:GET、POST、DELETE、HEAD、OPTIONS、PUT、TRACE
- 请求URL:它和报文头的Host属性组成完整的请求URL
- HTTP协议及版本
- 示例: “POST https://mcs.snssdk.com/list HTTP/1.1”
- 组成
- HTTP头(通用信息头,请求头,实体头)
- 常见的请求标头字段,全部字段看MDN
- Accept:通过该字段告诉服务端客户端接受什么类型的响应
- Origin:
- User-Agent
- Content-Type
- Referer:表示这个请求是从哪个URL过来的
- Host:请求主机及端口号
- Cache-Control:缓存控制
- cookie:客户端Cookie
- 常见的请求标头字段,全部字段看MDN
- 请求报文主体
- 只有发送Post请求时有请求报文主体
- 请求行
- 响应报文
- 状态行
- 组成
- 报文协议及版本
- 状态码及状态描述
- 示例:“HTTP/1.1 200 OK”
- 组成
- HTTP头(通用信息头,响应头,实体头)
- 常见的响应标头字段,全部字段看MDN
- Access-Control-Allow-Origin
- Content-Type
- Date
- Etag
- Last-Modified
- 常见的响应标头字段,全部字段看MDN
- 响应报文主体
- 状态行
通用信息头指的是请求和响应报文都支持的头域,分别为
Cache-Control、Connection、Date、Pragma、Transfer-Encoding、Upgrade、Via; 实体头则是实体信息的实体头域,分别为Allow、Content-Base、Content-Encoding、Content-Language、Content-Length、Content-Location、Content-MD5、Content-Range、Content-Type、Etag、Expires、Last-Modified、extension-header。这里只是为了方便理解,将通用信息头,响应头/请求头,实体头都归为了HTTP头。
TCP vs UDP
TCP/IP网络模型 TCP/IP 是互联网相关的各类协议族的总称,比如:TCP,UDP,IP,FTP,HTTP,ICMP,SMTP 等都属于 TCP/IP 族内的协议。
TCP/IP模型是互联网的基础,它是一系列网络协议的总称。这些协议可以划分为四层,分别为链路层、网络层、传输层和应用层。
- 链路层:负责封装和解封装IP报文,发送和接受ARP/RARP报文等。
- 网络层:负责路由以及把分组报文发送给目标网络或主机。
- 传输层:负责对报文进行分组和重组,并以TCP或UDP协议格式封装报文。
- 应用层:负责向用户提供应用程序,比如HTTP、FTP、Telnet、DNS、SMTP等。
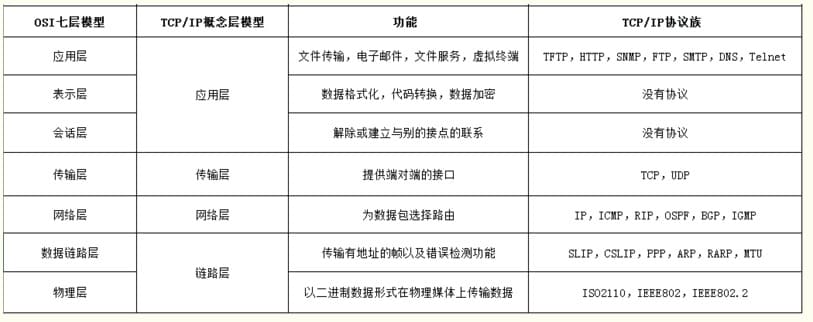
UDP UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说,当报文发送之后,是无法得知其是否安全完整到达的。 它有以下几个特点:
- 面向无连接
首先 UDP 是不需要和 TCP一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。具体来说就是:
- 在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
- 在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
- 有单播,多播,广播的功能 UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
- UDP是面向报文的 发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
- 不可靠性
- 头部开销小,传输数据报文时是很高效的。 UDP 的头部开销小,只有八字节,相比 TCP 的至少二十字节要少得多,在传输数据报文时是很高效的
TCP TCP协议全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议,由 IETF 的RFC 793定义。TCP 是面向连接的、可靠的流协议。流就是指不间断的数据结构,你可以把它想象成排水管中的水流 它有以下几个特点:
- 面向连接 面向连接,是指发送数据之前必须在两端建立连接。建立连接的方法是“三次握手”,这样能建立可靠的连接。建立连接,是为数据的可靠传输打下了基础。
- 仅支持单播传输 每条TCP传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式。
- 面向字节流 TCP不像UDP一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输。
- 可靠传输 对于可靠传输,判断丢包,误码靠的是TCP的段编号以及确认号。TCP为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传。
- 提供拥塞控制 当网络出现拥塞的时候,TCP能够减小向网络注入数据的速率和数量,缓解拥塞
- TCP提供全双工通信 TCP允许通信双方的应用程序在任何时候都能发送数据,因为TCP连接的两端都设有缓存,用来临时存放双向通信的数据。当然,TCP可以立即发送一个数据段,也可以缓存一段时间以便一次发送更多的数据段(最大的数据段大小取决于MSS)
对比
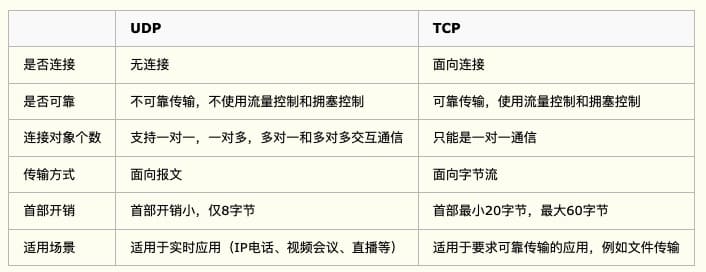
总结 TCP向上层提供面向连接的可靠服务 ,UDP向上层提供无连接不可靠服务。 虽然 UDP 并没有 TCP 传输来的准确,但是也能在很多实时性要求高的地方有所作为 对数据准确性要求高,速度可以相对较慢的,可以选用TCP
TCP 三次握手和 四次挥手
三次握手用于建立一个 TCP 连接,详情请看上面的讲解
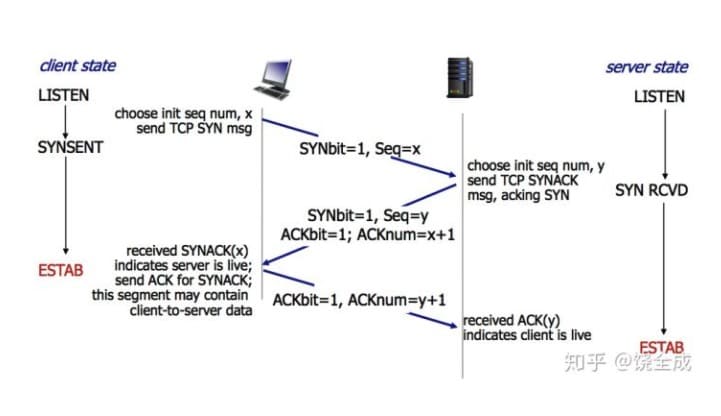 为什么需要三次握手?
三次握手主要是client和service确认对方是否有发送消息和接收消息的能力
第一次握手成功,service知道client有发送消息的能力
第二次握手成功,client知道service有发送和接收消息的能力
第三次握手,service知道client有接收消息的能力
如果只有两次握手,那么service就不能确保client有接收消息的能力了!
我们来想象一个场景,client发送了第一个请求包,由于网络的原因没有立马发送到service,然后client的超时时间设置的比较短并且因为超时主动断开了连接,但是这个请求包最后还是被service接收到了(因为网络导致的延误),如果只有二次握手,service就会认为连接确认了,开始一直等待client继续跟他通信,做了无用的等待,导致这种情况的原因就是service没有去确保client有接收消息的能力
为什么需要三次握手?
三次握手主要是client和service确认对方是否有发送消息和接收消息的能力
第一次握手成功,service知道client有发送消息的能力
第二次握手成功,client知道service有发送和接收消息的能力
第三次握手,service知道client有接收消息的能力
如果只有两次握手,那么service就不能确保client有接收消息的能力了!
我们来想象一个场景,client发送了第一个请求包,由于网络的原因没有立马发送到service,然后client的超时时间设置的比较短并且因为超时主动断开了连接,但是这个请求包最后还是被service接收到了(因为网络导致的延误),如果只有二次握手,service就会认为连接确认了,开始一直等待client继续跟他通信,做了无用的等待,导致这种情况的原因就是service没有去确保client有接收消息的能力
什么是四次挥手?
四次挥手即终止TCP连接,在socket编程中,这一过程由客户端或服务端任一方执行close来触发。由于TCP连接是全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭。
挥手请求可以是Client端,也可以是Server端发起的,我们假设是Client端发起:
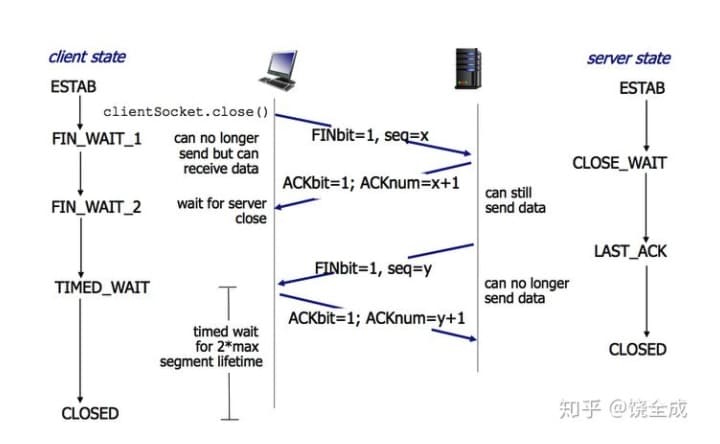
- 第一次挥手:Client 发送标志位是
FIN报文段,同时设置序列号seq(自己的当前序号)和ACK表示确认对方最近一次发过来的数据,此时,Client端进入FIN_WAIT_1状态,这表示Client端没有数据要发送给Server端了。 - 第二次挥手:Server向Client返回一个标志位是
ACK的报文段,ack设为seq+1,Client端进入FIN_WAIT_2状态,Server端告诉Client端,我确认并同意你的关闭请求,这时上层的应用程序会被告知另一端发起了关闭操作,通常这将引起应用程序发起自己的关闭操作。 - 第三次挥手:Server端向Client端发送标志位是
FIN的报文段(当然也会设置ACK、seq和ack),请求关闭连接,同时Service端进入LAST_ACK状态。 - 第四次挥手 :Client端向Server端发送标志位是
ACK的报文段,然后Client端进入TIME_WAIT状态。Server端收到Client端的ACK报文段以后,就关闭连接。此时,Client端等待2MSL的时间后依然没有收到回复,则证明Server端已正常关闭,那好,Client端也可以关闭连接了。
为什么连接的时候是三次握手,关闭的时候却是四次握手? 建立连接时因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。所以建立连接只需要三次握手。
关闭连接时,因为TCP是全双工模式,当当有一端请求关闭时,另一端还是可以发送消息的,需要等到另一端也没有数据要发送时才能关闭连接
为什么要等待2MSL?
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。 有以下两个原因:
- 第一点:保证TCP协议的全双工连接能够可靠关闭: 由于IP协议的不可靠性或者是其它网络原因,导致了Server端没有收到Client端的ACK报文,那么Server端就会在超时之后重新发送FIN,如果此时Client端的连接已经关闭处于CLOESD状态,那么重发的FIN就找不到对应的连接了,从而导致连接错乱,所以,Client端发送完最后的ACK不能直接进入CLOSED状态,而要保持TIME_WAIT,当再次收到FIN的收,能够保证对方收到ACK,最后正确关闭连接。
- 第二点:保证这次连接的所有数据段从网络中消失 如果Client端发送最后的ACK直接进入CLOSED状态,然后又再向Server端发起一个新连接,这时不能保证新连接的与刚关闭的连接的端口号是不同的,也就是新连接和老连接的端口号可能一样了,那么就可能出现问题:如果前一次的连接某些数据滞留在网络中,这些延迟数据在建立新连接后到达Client端,由于新老连接的端口号和IP都一样,TCP协议就认为延迟数据是属于新连接的,新连接就会接收到脏数据,这样就会导致数据包混乱。所以TCP连接需要在TIME_WAIT状态等待2倍MSL,才能保证本次连接的所有数据在网络中消失。